


Can AI read emotions in eyes?
Testing some approaches

In the last few years, many computer vision tasks have gone from virtually impossible to quite easy. A task that is hard even for many humans is recognising emotions from a picture of the eyes alone. To see how easy this is with some recent AI developments, I tried out some approaches (Github repository with implementations).

CLIP
The first approach I tried is to use CLIP. CLIP provides a mapping (referred to as an “embedding”) from text to high-dimensional vectors, and a mapping from images to vectors (of the same dimension as for text). If the text describes the image well, then their embedding vectors should point in similar directions.
This suggests a way to detect emotions. Simply embed the image and also embed some possible labels. Then the predicted emotion is the one whose label most closely matches the image. To test this, I used images and options from this test. However, a caveat here is that these images may be in the training dataset of CLIP!
This approach does significantly better than chance. It is correct about 50% of the time (p-value of 0.0029 if there are 4 options) on the sample of 22 images that I tried.
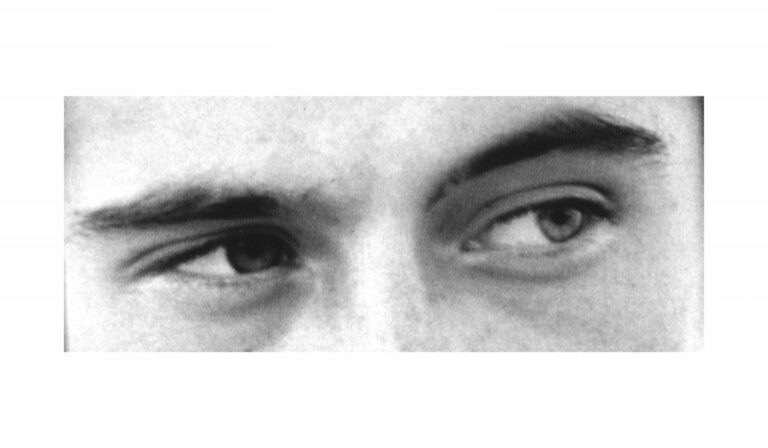

OpenCLIP
One low-hanging fruit improvement is to use a better CLIP model. This didn’t end up helping though: using one of the largest models available in the OpenCLIP library had exactly the same accuracy on my sample as the smaller CLIP model.
Asking a language model
Another approach is to just ask a multimodal language model what emotion it thinks the image shows. This gave a pretty big improvement. I used the Anthropic API to automatically ask Claude 3 to guess what emotion each face showed.
This got up to 72% accuracy!
Interestingly, the best performance was with Claude Haiku, the smallest model. The larger Claude Opus scored only 16%, sometimes failing to even pick one of the multiple choice options. Another interesting quirk is that if you ask Haiku to describe the emotion without providing options, it almost invariably says “intensity”. Which is not totally wrong, for a closeup of the eyes.
I would actually expect it to be correct more often. After all isn't this just pattern recognition?